Weedata
Weedata ist ein leichtgewichtiges Tool zur strukturierten Datenerfassung, das im Rahmen des DIKUSA-Projekts von der Werkstatt des KompetenzwerkD entwickelt wurde. Ziel dabei war es, ein flexibles System zum Aufbau kleinerer Wissensbasen zu entwickeln, das ohne großen weiteren Entwicklungsaufwand für kleinere bis mittelgroße geisteswissenschaftliche Forschungsprojekte eingesetzt werden kann.
Datenmodellierung
Datenmodellierung ist ein integrierter Bestandteil der Weedata-Webapplikation. Über die Anwendungsoberfläche können Klassen und Properties für Entitäten (Personen, Orte, etc.) definiert werden. Weedata stellt dabei ein breites Spektrum an Datentypen zur Verfügung (Text, Datum, Zahlenwerte, URLS, Geoinformationen etc.). Die in Weedata erstellten Datenmodelle können dabei als OWL-RDF Ontologie exportiert und auch wieder importiert werden. Die Klassen und Properties können weiter auf bestehende Ontologien wie CIDOC-CRM gemappt werden. Neben den Klassen und Properties können auch kontrollierte Vokabulare (sowohl einfache Wortlisten als auch komplexere hierarchische Taxonomien) in Weedata verwaltet werden. Auch hier können über die Benutzeroberfläche neue Vokabulare angelegt werden, oder es können auch existierende Vokabulare im SKOS-Format importiert werden.
Datenerfassung
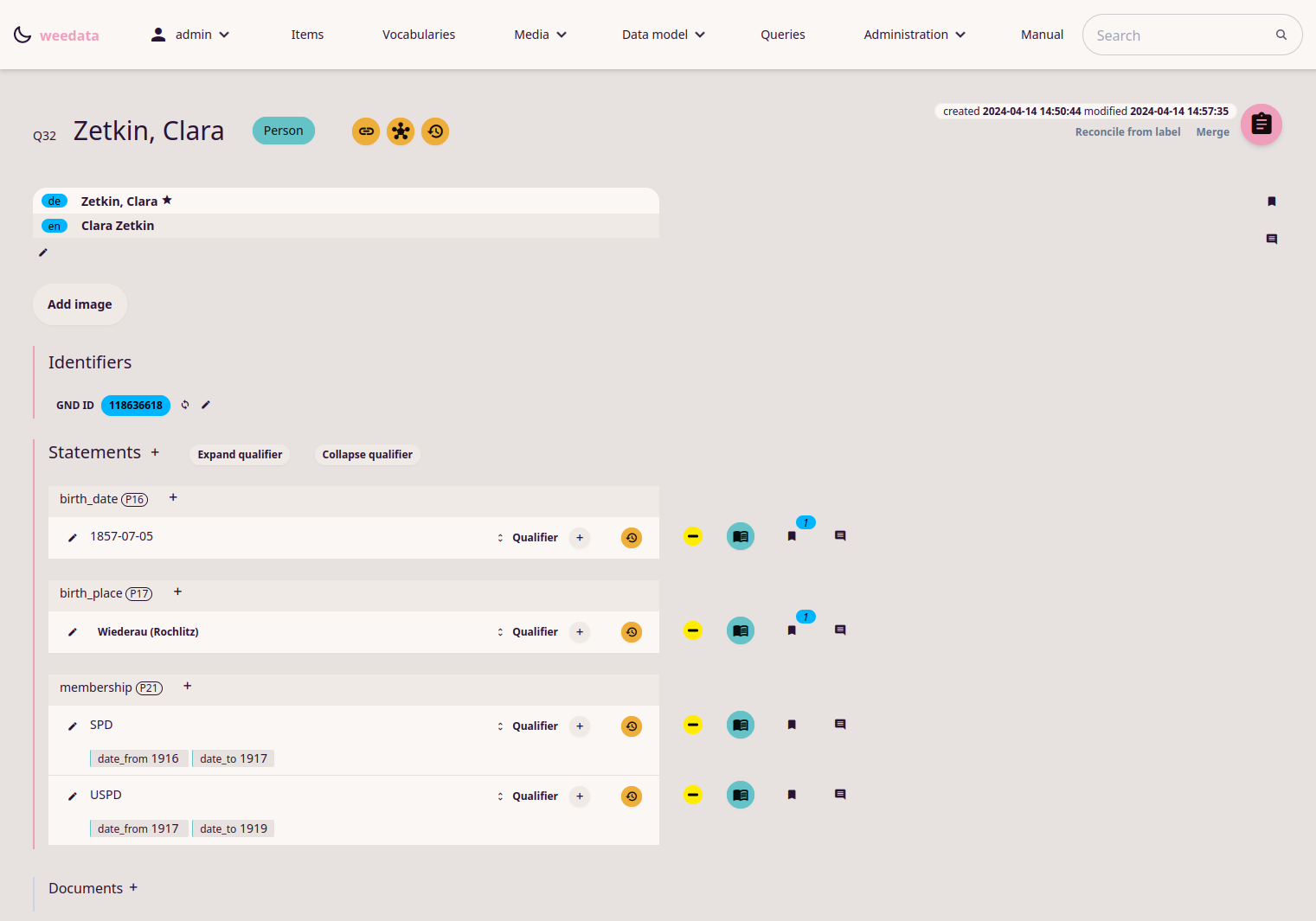
Daten werden in Weedata entsprechend dem erstellten Datenmodell erfasst. Die Struktur ist dabei an Wikidata angelehnt: Einzelne Items werden als Instanzen der jeweiligen Klasse erstellt (z. B. das Item 'Leipzig' der Klasse 'Ort). Zu dem Items können weitere Informationen in Form von semantischen Tripels ("Leipzig" (Item), "hat Einwohnerzahl" (Property), 587.000 (Wert) erfasst werden. Diese Statements können auch wieder durch weitere Informationen ausgezeichnet werden. Damit können selbst komplexere Sachverhalte repräsentiert werden.
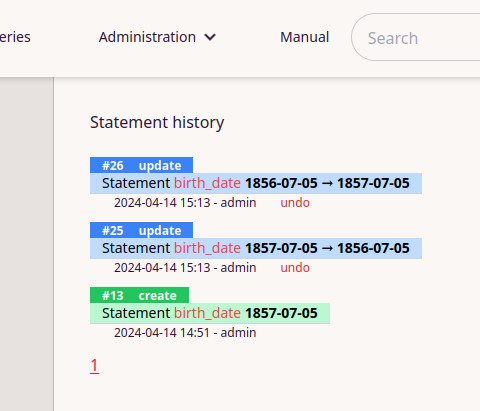
Sämtliche Änderungen an den Informationen in der Wissensbasis (Erstellen, Löschen, Verändern) sind über eine History einsehbar und können gegebenenfalls auch wieder Rückgängig gemacht werden.
Zu jedem Item und jedem Statement in der Wissensbasis können weitere Metadaten erfasst werden: Kommentare, Informationen über die Datenherkunft (Provenance) und Angaben über die Korrektheit der Daten können bequem über die Benutzeroberfläche eingetragen werden.
Kollaboratives Arbeiten
Neben vollwertigen Zugängen können auch Benutzer für Personen angelegt werden können, die nur einen eingeschränkten Zugriff auf die Datenbank erhalten sollen (z. B. "Editors" für Mitarbeiter:innen, die nur Items und Statements bearbeiten können oder "Guests" für Personen, die nur einen Lesezugriff auf die Daten erhalten sollen).
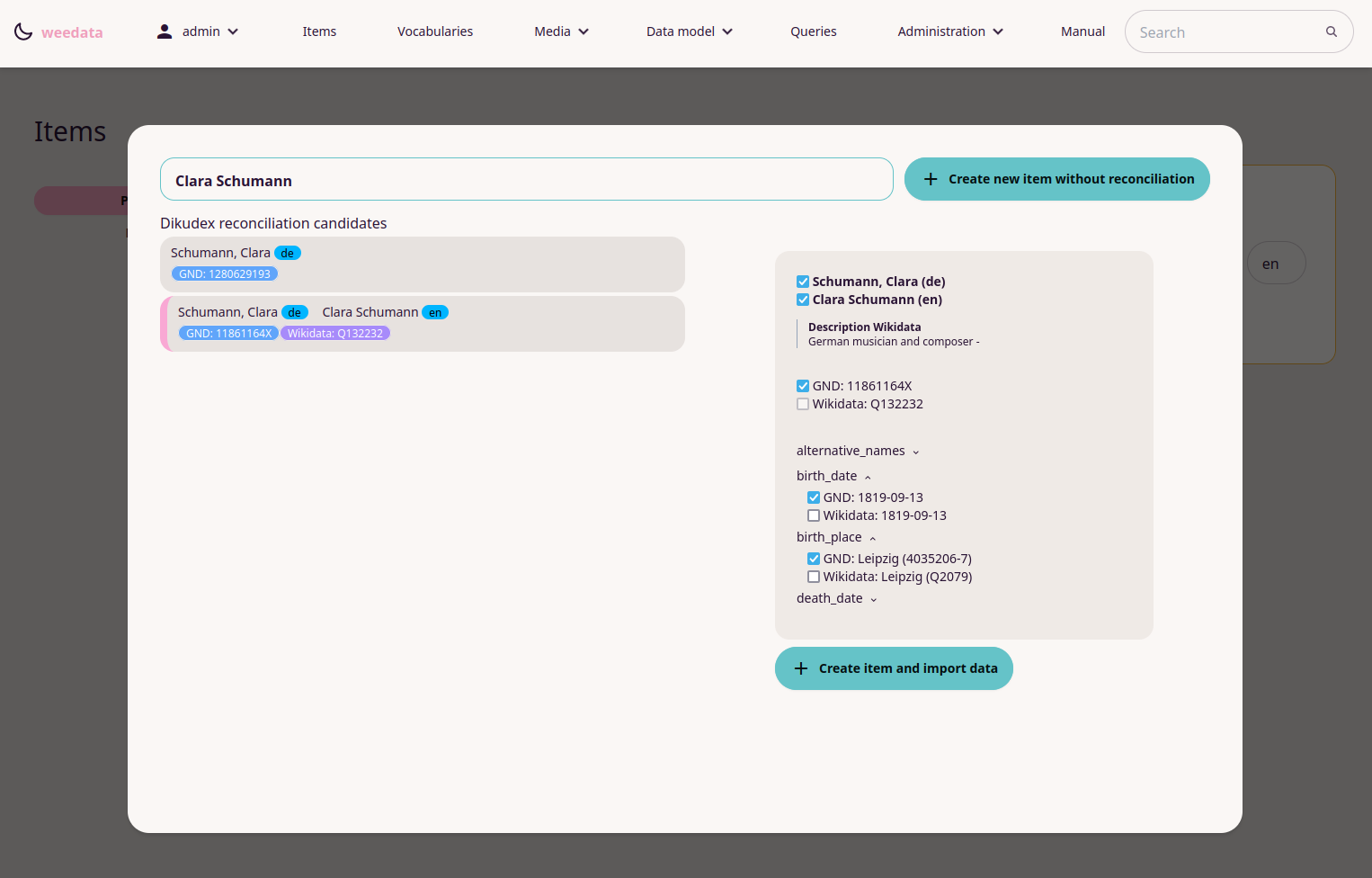
Reconciliation von Normdaten
Durch die Integration von des Reconciliation-Services Dikúdex kann beim Anlegen von Items gleich nach Verlinkungen zu Normdaten wie der GND gesucht werden und zusätzliche Informationen aus den Normdaten in die Wissensbasis mit übernommen werden.