In den DIKUSA-Projekten sind durch Aufarbeitung wissenschaftlicher Quellen digitale Wissensbasen entstanden. Dies ist unter Verwendung unterschiedlicher Lösungen zur Datenerfassung - wie dem im Projekt entstandenen Tool Weedata - in an die jeweilige Forschungsfrage angepassten Datenmodellen erfolgt. Um eine spätere Integration der Datensätze zu erleichtern, wurde verstärkt auf den Einsatz von Normdaten wie GND oder Wikidata geachtet.
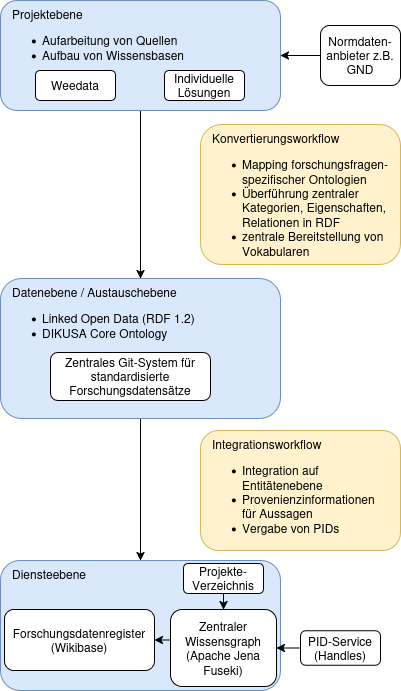
Um dem Ziel des Zusammenführens der in den Projekten entstehenden Daten näher zu kommen, wurde die DIKUSA Core Ontology (DCO) als gemeinsames Datenmodell entwickelt, in das die Daten aus den Wissensbasen der DIKUSA-Projekte konvertiert wurden. Dabei wurden zentrale Kategorien sowie typische Eigenschaften von Entitäten und übliche Beziehungen zwischen ihnen abgebildet. Die Datensätze sind über das gitlab-System der Sächsischen Akademie der Wissenschaften zu Leipzig abrufbar und werdne auch von dort für die Datenintegration bezogen. Gleichzeitig wurden kontrollierte Vokabulare von zentraler Bedeutung identifiziert, mit persistenten Identifikatoren versehen und in einem gemeinsamen Skosmos-System abgelegt, umd die enthaltenen Konzepte auflösbar zu machen und eine Recherchierbarkeit zu gewährleiosten.
Um nun zentrale Dienste anbieten zu können, erfolgt ein Zusammenführen der Daten der DIKUSA-Projekte. Die Integration wird auf der Ebene der Entitäten (wie Orte, Personen, Institutionen) durchgeführt, indem Normdatenverknüpfungen berücksichtigt werden. Provinienzangaben werden übernommen bzw. ergänzt, um später alle Aussagen möglichst auf ihren Ursprung zurückführen zu können. Schließlich erfolgt eine Vergabe von persistenten Identifikatoren, um eine dauerhafte Referenzierbarkeit zu gewährleisten und für die erfassten Kulturdaten einen eigenen Referenzindex aufbauen zu können.
So entsteht zunächst ein zentraler Wissensgraph, der sich aus den Daten der Projekte speist und diese integriert bereitstellt. Der Graph basiert auf RDF, folgt dem Schema der DIKUSA Core Ontology und wird mittels Apache Jena Fuseki, eines Speichers für Wissensgraphen mit SPARQL-Schnittstelle, entsprechend der Linked Open Data-Prinzipien frei zugänglich gemacht.
Zur Darstellung der Inhalte des zentralen Wissensgraphen wurde ein Prototyp eines Forschungsdatenregisters erstellt.
Das Register soll eine Übersicht zu in Projekten entstandenen Datensätzen ermöglichen und Einblick geben, in welchen Projekten zu spezifischen Entitäten geforscht wurde. Die Umsetzung erfolgt auf Basis von Wikibase. Das Wikibase-System erlaubt eine übersichtliche Darstellung strukturierter und verknüpfter Daten und ermöglicht deren Recherchierbarkeit – zentrale Anliegen des Registers.
Im Gegensatz zum Wissensgraph mit seinem universellen, aber komplexen und verschachtelten Datenmodell setzt das Register dabei auf eine flache, kompakte und übersichtliche Struktur mit dem Fokus auf Menschenlesbarkeit. Dabei werden für Entitäten der Hauptkategorien wie Personen, Orte und Institutionen jeweils auf eigenen Unterseiten zentrale Relationen und Attribute dargestellt und stets mit Provenienzinformationen unterlegt.
Absehbar soll der zentrale Wissensgraph bzw. das Register als Basis für einen Reconciliationdienst dienen und in die bestehende Dikúdex-Infrastruktur integriert werden. Dies soll eine Referenzierbarkeit sicherstellen und eine Integration zukünftiger Forschungsdaten ermöglichen.
Durch das beschriebene Vorgehen entsteht eine erweiterbare Infrastruktur, die es den geisteswissenschaftlichen Forschungseinrichtungen in Sachsen erleichtert, digitale Forschungsprojekte durchzuführen, Daten zu erfassen und zu verknüpfen, ohne für jeden Einzelaspekt individuelle Lösungen konzipieren zu müssen.
In den Teilprojekten sind bei der Erstellung der Wissensbasen vielfach Sammlungen von Bezeichnern - sogenannte kontrollierte Vokabulare - entstanden. Derartige Begriffslisten bzw. -hierarchien sind wertvolle Ressourcen zur Beschreibung von Daten, auch in zukünftigen Projekten. Daher wurden derartige Vokabulare aus den Wissensbasen extrahiert und in der verbreiteten Beschreibungssprache skos zunächst über github zugänglich gemacht.
cUm die kontrollierten Vokabulare auch offen zugänglich in menschenlesbarer Form anbieten zu können, wurde zusätzlich ein Skosmos eingerichtet, ein System zur Darstellung und Verwaltung von Vokabularen. Auf diese Weise wird eine Recherchierbarkeit in den mit ihren Metadaten abgelegten Ressourcen gewährleistet. Gleichzeitig bietet sich skosmos an, um die enthaltenen Konzepte auflösbar zu machen, ihnen also eine feste URL zuzuordnen unter der sie gefunden werden können. Durch die Verwendung von PIDs (auf purl-Basis) wird diese Referenzierbarkeit dauerhaft gewährleistet und durch Verweise auf die Originaldaten ist auch diese Verbindung hergestellt.